Saya pikir itu yang terbaik jika saya menguraikan poin kedua Anda dengan contoh langkah dalam game 1 antara AlphaZero dan Stockfish yang juga berfungsi untuk memuaskan rasa ingin tahu saya hari ini.
batas waktu 1 menit / langkah (Bagaimana ini merugikan Stockfish?)
Performa Stockfish tergantung pada batas waktu dan konfigurasi perangkat keras, jadi pikirkan ketika seseorang menggandakan utas CPU, maka Stockfish membutuhkan lebih sedikit waktu (tidak perlu setengah) untuk menemukan solusinya daripada dengan konfigurasi pertama.
Pada laporan pertama yang diposting di Chess.com seseorang mengklaim bahwa Stockfish tidak bermain secara optimal karena dia tidak dapat mereproduksi hasil yang sama menggunakan Stockfish yang sama di komputernya. Dia mengatakan bahwa pada posisi di bawah (game 1 - move 11) Stockfish memainkan Kg1-h1 (memindahkan rajanya) yang tidak masuk akal sama sekali. Di sisi lain, stockfish di komputernya menunjukkan gerakan yang lebih berkembang seperti Be3 (memindahkan uskup kotak gelap), mari kita lihat posisi:
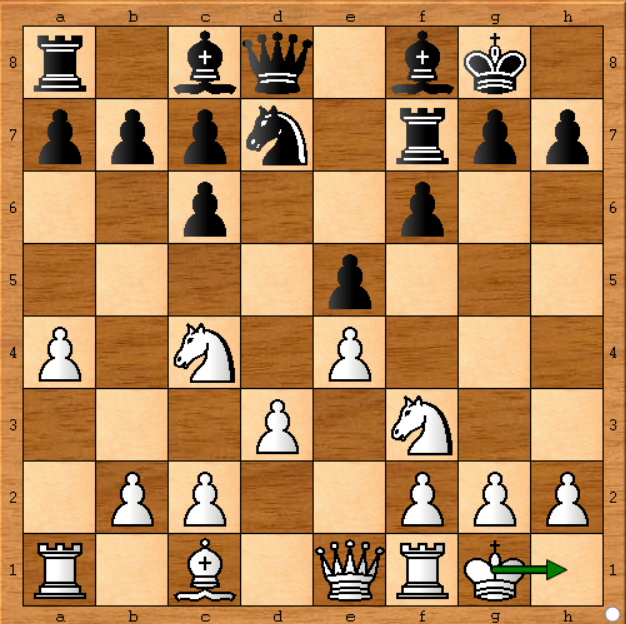
Ya, itu adalah langkah pasif dan sepertinya Stockfish seharusnya memainkan langkah yang lebih berkembang. Tapi dia salah. Mengapa? Karena dia menjalankan Stockfish selama 15 detik, dan jika dia menjalankannya selama satu jam, dia akan mendapatkan Kg1-h1 sebagai langkah terbaik di posisi itu. Stockfish mengubah keputusannya ketika menganalisis semua kemungkinan pergerakan secara lebih mendalam. Inilah yang awalnya saya katakan dalam balasan saya :
Saya menjalankan stockfish terbaru pada posisi (pada langkah 11):
- Pada awalnya, ini memberikan b4 sebagai langkah optimal ketika mesin berjalan sekitar satu menit. Setelah itu, diputuskan Be3 lebih baik.
Tetapi setelah 5 menit pada perangkat keras saya yang berjalan pada 1.400 k node / s itu akan memutuskan untuk pergi dengan Kh1 sebagai langkah optimal.
Di koran, dikatakan bahwa stockfish menghitung 70.000k posisi per detik dan dijalankan selama 1 menit per gerakan, itu sekitar 50 kali perangkat keras saya, jadi saya akan membiarkan tambang berjalan selama 50 menit ... Kg1-h1 masih merupakan pilihan untuk Stockfish.
Batas waktu adalah kuncinya
Dalam kasus di atas, mungkin tidak masalah jika Stockfish berlari dua kali karena keputusannya akan sama, tetapi pada langkah selanjutnya pasti akan :
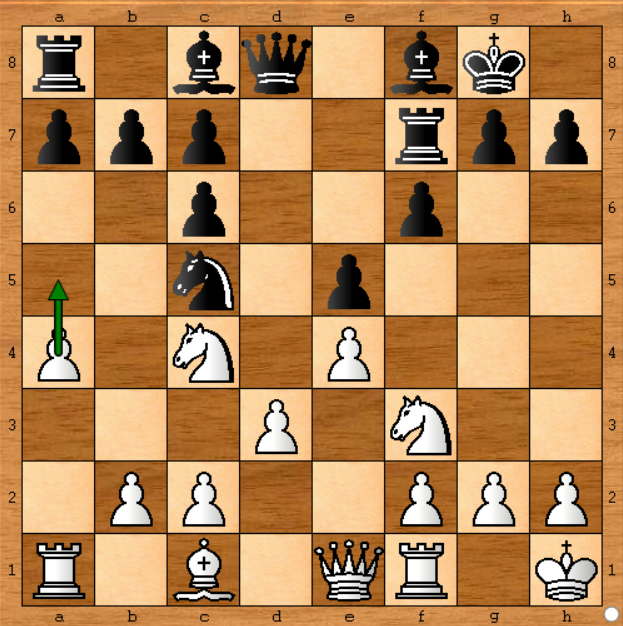
Di posisi ini, Stockfish memilih untuk memindahkan pion di sisi kiri ( a4-a5 ). Katakanlah saya memiliki komputer yang menjalankan mesin Stockfish pada kecepatan 1.400 k node per detik, itu sekitar 50 kali lebih rendah daripada Stockfish di game nyata ( Di koran , katanya 70.000kn / s). Jadi saya bisa mensimulasikan permainan jika saya menjalankannya selama 50 menit di setiap gerakan. Baik.
Saya menjalankan analisis Stockfish pada posisi di atas dan saya mendapatkan hasil sebagai berikut:
- Stockfish mulai menyarankan beberapa gerakan, tetapi setelah 6 menit di komputer saya (sesuai dengan 7,2 detik pada Stockfish dalam permainan nyata) itu lebih suka a4-a5 seperti permainan berjalan .
Itu bagus, tapi saya tetap menjalankannya selama 50 menit untuk mencapai perhitungan Stockfish dalam permainan yang diizinkan 1 menit:
Kebenaran yang menyedihkan adalah bahwa saya percaya Stockfish kehilangan semua gimnya karena batas waktu. Stockfish mendapatkan pencarian dan evaluasi yang lebih mendalam seiring berjalannya waktu dan dalam permainan itu tidak diizinkan untuk menggunakan buku pembuka yang membuatnya mempertimbangkan banyak gerakan di kedalaman yang dangkal. Perhatikan bahwa dalam permainan sebenarnya a4-a5 dimainkan yang menunjukkan bahwa (dengan asumsi itu dapat mengevaluasi 70 juta posisi per detik) Stockfish dalam permainan tidak menghabiskan lebih dari 21,6 detik untuk bergerak. Jika tidak, itu akan mengubah keputusannya menjadi tiga gerakan lain dalam permainan yang sebenarnya. Alasan untuk ini masih belum jelas bagi saya karena Stockfish saya juga mengkonsumsi lebih sedikit memori (sekitar ~ 130MB RAM dibandingkan dengan 1GB yang disebutkan dalam kertas asli , dengan asumsi semua itu masuk ke tabel hash).
Kesimpulan
Perangkat keras yang menjalankan Stockfish, seperti yang saya tunjukkan, adalah yang terbaik 18 kali lebih cepat daripada milik saya (Pembaruan: pada satu inti) berdasarkan langkah yang saya analisis. Saya tidak yakin apakah AlphaZero benar-benar dapat menggunakan perangkat keras seperti itu untuk melatih jaringannya dalam 4 jam, saya hanya bisa menganggap itu terlalu rendah untuk permainan seperti catur. Selain itu, AlphaZero menghabiskan waktu itu untuk belajar yang juga mencakup membangun bukaan yang solid (dan seperti yang ditunjukkan makalah ini, preferensi atas bukaan tertentu). Di sisi lain, Stockfish cacat pada bukaan, dan itu tidak mengevaluasi 70 juta posisi per detik selama 60 detik pada setiap gerakan.
Sebagai catatan terakhir, semua hal yang saya katakan didasarkan pada asumsi saya. Tentu saja, hasil AlphaZero dan permainannya sangat menarik bagi saya. Namun, saya ingin sekali melihat permainan di mana permainan Stockfish sama seperti yang saya dapatkan di komputer saya juga. Artinya, lebih banyak waktu dan buku pembuka diperbolehkan. Juga mudah untuk mendapatkan output dari analisis Stockfish di setiap gerakan, dan saya berharap mereka merilisnya untuk menunjukkan seberapa baik kinerjanya.