Saya sudah memiliki pertanyaan ini selama berbulan-bulan. Sepertinya kita hanya dengan pintar menebak softmax sebagai fungsi output dan kemudian menafsirkan input ke softmax sebagai probabilitas log. Seperti yang Anda katakan, mengapa tidak hanya menormalisasi semua output dengan membagi dengan jumlah mereka? Saya menemukan jawabannya dalam buku Deep Learning oleh Goodfellow, Bengio dan Courville (2016) di bagian 6.2.2.
Katakanlah layer tersembunyi terakhir kita memberi kita z sebagai aktivasi. Kemudian softmax didefinisikan sebagai

Penjelasan Sangat Singkat
Exp dalam fungsi softmax secara kasar membatalkan log dalam kehilangan lintas-entropi yang menyebabkan kerugian menjadi linear di z_i. Ini mengarah ke gradien yang kira-kira konstan, ketika modelnya salah, memungkinkannya untuk memperbaiki dirinya sendiri dengan cepat. Jadi, softmax jenuh yang salah tidak menyebabkan gradien hilang.
Penjelasan Singkat
Metode yang paling populer untuk melatih jaringan saraf adalah Estimasi Kemungkinan Maksimum. Kami memperkirakan parameter theta dengan cara yang memaksimalkan kemungkinan data pelatihan (ukuran m). Karena kemungkinan seluruh dataset pelatihan adalah produk dari kemungkinan masing-masing sampel, lebih mudah untuk memaksimalkan kemungkinan log dari dataset dan dengan demikian jumlah kemungkinan log dari masing-masing sampel diindeks oleh k:
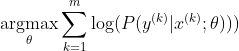
Sekarang, kita hanya fokus pada softmax di sini dengan z yang sudah diberikan, jadi kita bisa menggantinya
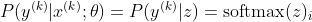
dengan saya menjadi kelas sampel kth yang benar. Sekarang, kita melihat bahwa ketika kita mengambil logaritma dari softmax, untuk menghitung kemungkinan log sampel, kita mendapatkan:
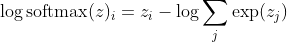
, yang untuk perbedaan besar dalam z kira-kira mendekati
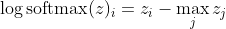
Pertama, kita melihat komponen linear z_i di sini. Kedua, kita dapat memeriksa perilaku max (z) untuk dua kasus:
- Jika modelnya benar, maka maks (z) akan menjadi z_i. Dengan demikian, kemungkinan log asimtot nol (yaitu kemungkinan 1) dengan perbedaan yang berkembang antara z_i dan entri lainnya di z.
- Jika modelnya salah, maka maks (z) akan menjadi beberapa z_j> z_i lainnya. Jadi, penambahan z_i tidak sepenuhnya membatalkan -z_j dan log-likelihood kira-kira (z_i - z_j). Ini dengan jelas memberi tahu model apa yang harus dilakukan untuk meningkatkan kemungkinan log: meningkatkan z_i dan mengurangi z_j.
Kami melihat bahwa kemungkinan log secara keseluruhan akan didominasi oleh sampel, di mana modelnya tidak benar. Juga, bahkan jika model ini benar-benar salah, yang mengarah ke softmax jenuh, fungsi kerugian tidak jenuh. Ini kira-kira linear dalam z_j, artinya kita memiliki gradien yang konstan konstan. Ini memungkinkan model untuk memperbaiki dirinya sendiri dengan cepat. Perhatikan bahwa ini bukan kasus untuk Mean Squared Error misalnya.
Penjelasan Panjang
Jika softmax masih tampak sebagai pilihan yang sewenang-wenang bagi Anda, Anda dapat melihat pembenaran untuk menggunakan sigmoid dalam regresi logistik:
Mengapa fungsi sigmoid bukan yang lain?
Softmax adalah generalisasi dari sigmoid untuk masalah multi-kelas dibenarkan secara analog.



