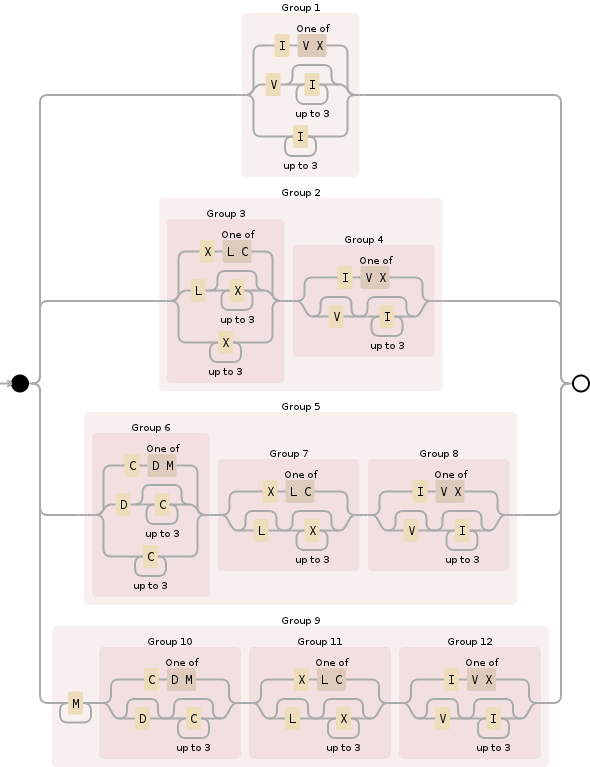
Anda dapat menggunakan regex berikut untuk ini:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Memecahnya, M{0,4}menentukan bagian ribuan dan pada dasarnya menahannya antara 0dan 4000. Ini relatif sederhana:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
Anda bisa, tentu saja, menggunakan sesuatu seperti M*mengizinkan angka berapa pun (termasuk nol) ribuan, jika Anda ingin memperbolehkan angka yang lebih besar.
Berikutnya adalah (CM|CD|D?C{0,3}), sedikit lebih kompleks, ini untuk bagian ratusan dan mencakup semua kemungkinan:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
Ketiga, (XC|XL|L?X{0,3})ikuti aturan yang sama seperti bagian sebelumnya tetapi untuk tempat puluhan:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
Dan, akhirnya, (IX|IV|V?I{0,3})adalah bagian unit, penanganan 0melalui 9dan juga mirip dengan dua bagian sebelumnya (angka Romawi, meskipun keanehan tampak mereka, mengikuti beberapa aturan yang logis setelah Anda mengetahui apa yang mereka):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
Perlu diingat bahwa regex itu juga akan cocok dengan string kosong. Jika Anda tidak menginginkan ini (dan mesin regex Anda cukup modern), Anda dapat menggunakan pandangan ke belakang dan melihat ke depan:
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(Alternatif lain adalah hanya memeriksa bahwa panjangnya tidak nol sebelumnya).