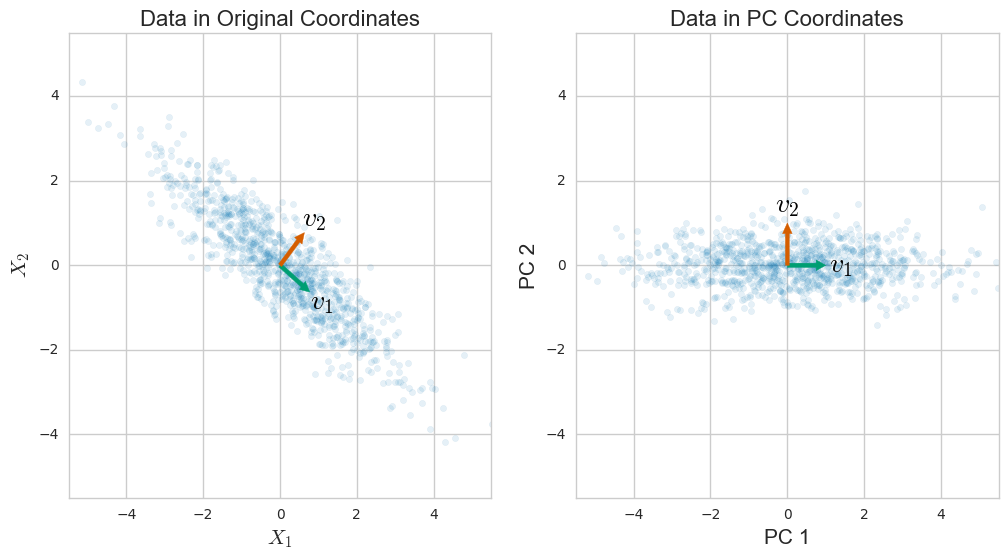
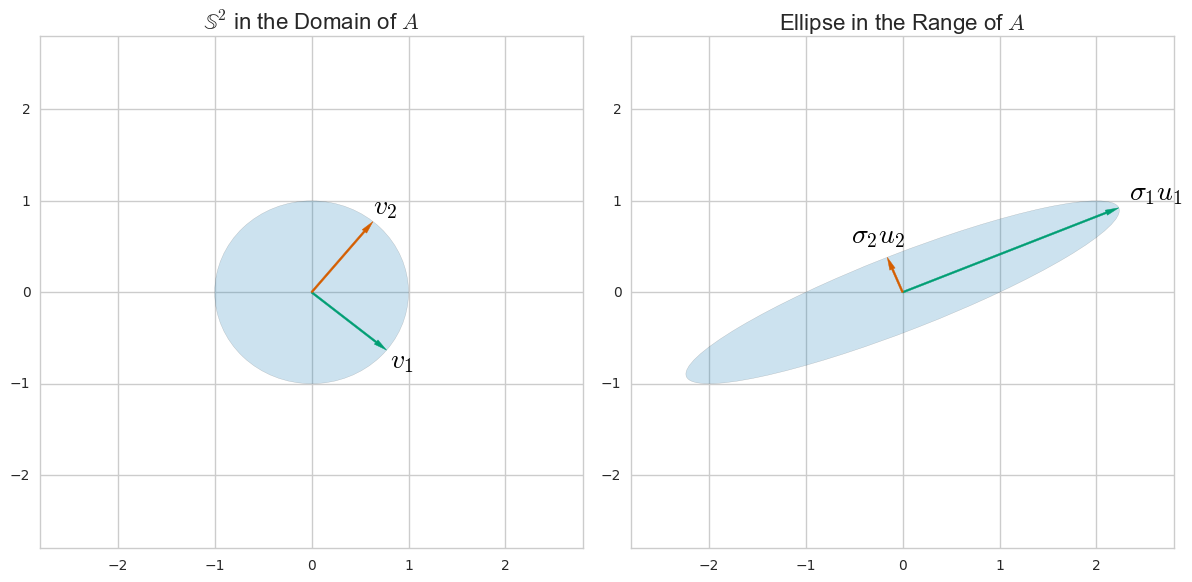
Analisis komponen utama (PCA) biasanya dijelaskan melalui dekomposisi eigen dari matriks kovarians. Namun, dapat juga dilakukan melalui dekomposisi nilai singular (SVD) dari data matriks . Bagaimana cara kerjanya? Apa hubungan antara kedua pendekatan ini? Apa hubungan antara SVD dan PCA?
Atau dengan kata lain, bagaimana cara menggunakan SVD dari matriks data untuk melakukan pengurangan dimensionalitas?
8
Saya menulis pertanyaan gaya-FAQ ini bersama dengan jawaban saya sendiri, karena sering ditanyakan dalam berbagai bentuk, tetapi tidak ada utas kanonik dan karenanya duplikat penutupan sulit. Berikan komentar meta di utas meta yang menyertainya ini .
—
amoeba
Selain jawaban amuba yang bagus dan terperinci dengan tautan lebih lanjutnya, saya mungkin merekomendasikan untuk memeriksa ini , di mana PCA dianggap berdampingan dengan beberapa teknik berbasis SVD lainnya. Diskusi di sana menyajikan aljabar yang hampir identik dengan amoeba dengan hanya sedikit perbedaan bahwa pidato di sana, dalam menggambarkan PCA, membahas tentang dekomposisi svd dari [atau ] bukannya - yang cukup mudah karena berkaitan dengan PCA yang dilakukan melalui komposisi eigend dari matriks kovarians. X/ √ X
—
ttnphns
PCA adalah kasus khusus SVD. PCA membutuhkan data yang dinormalisasi, unit yang idealnya sama. Matriksnya adalah nxn dalam PCA.
—
Orvar Korvar
@OrvarKorvar: Matriks nxn apa yang Anda bicarakan?
—
Cbhihe