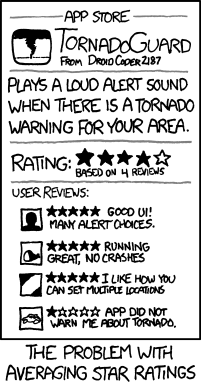
Manfaat menggunakan mean untuk meringkas kecenderungan sentral dari peringkat 5 poin
Seperti @gung sebutkan, saya pikir sering ada alasan yang sangat baik untuk mengambil rata-rata item lima poin sebagai indeks kecenderungan sentral. Saya sudah menguraikan alasan-alasan ini di sini .
Mengutip:
- rata-rata mudah dihitung
- Maksudnya adalah intuitif dan dipahami dengan baik
- Mean adalah angka tunggal
- Indeks lain sering menghasilkan urutan urutan objek yang serupa
Mengapa rata-rata baik untuk Amazon
Pikirkan tentang tujuan Amazon dalam melaporkan rata-rata. Mereka mungkin bertujuan
- memberikan peringkat yang intuitif dan mudah dipahami untuk suatu item
- memastikan penerimaan pengguna terhadap sistem peringkat
- memastikan bahwa orang-orang memahami arti peringkat sehingga mereka dapat menggunakannya dengan tepat untuk menginformasikan keputusan pembelian
Amazon menyediakan semacam rata-rata bulat, jumlah frekuensi untuk setiap opsi peringkat, dan ukuran sampel (yaitu, jumlah peringkat). Informasi ini mungkin cukup bagi kebanyakan orang untuk menghargai sentimen umum mengenai item tersebut dan kepercayaan pada peringkat seperti itu (yaitu, 4,5 dengan 20 peringkat lebih cenderung akurat daripada 4,5 dengan 2 peringkat; item dengan 10 5 peringkat-bintang, dan satu peringkat bintang-1 tanpa komentar mungkin masih merupakan barang bagus).
Anda bahkan dapat melihat nilai tengah sebagai pilihan demokratis. Banyak pemilihan diputuskan berdasarkan kandidat mana yang mendapatkan nilai rata-rata tertinggi dalam skala dua poin. Demikian pula, jika Anda mengambil argumen bahwa setiap orang yang mengirimkan ulasan mendapat suara, maka Anda dapat melihat mean sebagai bentuk yang menimbang suara setiap orang secara setara.
Apakah perbedaan dalam penggunaan skala benar-benar masalah?
Ada berbagai macam peringkat bias yang dikenal dalam literatur psikologis (untuk ulasan, lihat Saal et al 1980), seperti bias kecenderungan pusat, bias keringanan hukuman, bias ketat. Juga, beberapa penilai akan lebih sewenang-wenang dan beberapa akan lebih dapat diandalkan. Beberapa bahkan mungkin secara sistematis berbohong memberikan ulasan positif palsu atau negatif palsu. Ini akan membuat berbagai bentuk kesalahan ketika mencoba menghitung nilai rata-rata sebenarnya untuk suatu item.
Namun, jika Anda mengambil sampel acak dari populasi, bias semacam itu akan dibatalkan, dan dengan ukuran sampel yang cukup dari penilai, Anda masih akan mendapatkan nilai sebenarnya.
Tentu saja, Anda tidak mendapatkan sampel acak di Amazon, dan ada risiko bahwa serangkaian penilai yang Anda dapatkan untuk suatu item secara sistematis bias menjadi lebih lunak atau ketat dan sebagainya. Yang mengatakan, saya pikir pengguna Amazon akan menghargai bahwa peringkat yang dikirimkan pengguna berasal dari sampel yang tidak sempurna. Saya juga berpikir bahwa sangat mungkin bahwa dengan ukuran sampel yang masuk akal bahwa dalam banyak kasus, sebagian besar perbedaan bias respons akan mulai menghilang.
Kemungkinan ada kemajuan di luar rata-rata
Dalam hal meningkatkan akurasi peringkat, saya tidak akan menantang konsep umum rata-rata, tetapi saya pikir ada cara lain untuk memperkirakan peringkat rata-rata populasi sebenarnya untuk suatu barang (yaitu, nilai rata-rata yang akan diperoleh adalah sampel representatif besar yang diminta untuk menilai item).
- Penilai berat badan didasarkan pada kepercayaan mereka
- Gunakan sistem peringkat Bayesian yang memperkirakan peringkat rata-rata sebagai jumlah tertimbang dari peringkat rata-rata untuk semua item dan rata-rata dari item tertentu, dan meningkatkan bobot untuk item tertentu saat jumlah peringkat meningkat
- Sesuaikan informasi penilai berdasarkan kecenderungan peringkat umum di semua item (mis. Angka 5 dari seseorang yang biasanya memberi nilai 3 akan bernilai lebih dari seseorang yang biasanya memberikan nilai 4).
Jadi, jika akurasi dalam peringkat adalah tujuan utama Amazon, saya pikir itu harus berusaha untuk meningkatkan jumlah peringkat per item dan mengadopsi beberapa strategi di atas. Pendekatan semacam itu mungkin sangat relevan ketika menciptakan peringkat "terbaik". Namun, untuk peringkat sederhana pada halaman, mungkin berarti sampel lebih baik memenuhi tujuan kesederhanaan dan transparansi.
Referensi
- Saal, FE, Downey, RG & Lahey, MA (1980). Peringkat peringkat: Menilai kualitas psikometrik data peringkat .. Buletin Psikologis, 88, 413.