Mereka adalah dua metrik yang berbeda untuk mengevaluasi kinerja model Anda yang biasanya digunakan dalam fase yang berbeda.
Kehilangan sering digunakan dalam proses pelatihan untuk menemukan nilai parameter "terbaik" untuk model Anda (misalnya bobot dalam jaringan saraf). Inilah yang Anda coba optimalkan dalam pelatihan dengan memperbarui bobot.
Akurasi lebih dari perspektif terapan. Setelah Anda menemukan parameter yang dioptimalkan di atas, Anda menggunakan metrik ini untuk mengevaluasi seberapa akurat prediksi model Anda dibandingkan dengan data sebenarnya.
Mari kita gunakan contoh klasifikasi mainan. Anda ingin memprediksi jenis kelamin dari berat dan tinggi badan seseorang. Anda memiliki 3 data, mereka adalah sebagai berikut: (0 singkatan untuk pria, 1 singkatan untuk wanita)
y1 = 0, x1_w = 50kg, x2_h = 160cm;
y2 = 0, x2_w = 60kg, x2_h = 170cm;
y3 = 1, x3_w = 55kg, x3_h = 175cm;
Anda menggunakan model regresi logistik sederhana yaitu y = 1 / (1 + exp- (b1 * x_w + b2 * x_h))
Bagaimana Anda menemukan b1 dan b2? Anda mendefinisikan kerugian terlebih dahulu dan menggunakan metode optimisasi untuk meminimalkan kerugian dengan cara berulang dengan memperbarui b1 dan b2.
Dalam contoh kami, kerugian tipikal untuk masalah klasifikasi biner ini adalah: (tanda minus harus ditambahkan di depan tanda penjumlahan)

Kita tidak tahu apa yang seharusnya b1 dan b2. Mari kita membuat tebakan acak katakan b1 = 0,1 dan b2 = -0,03. Lalu apa kerugian kita sekarang?
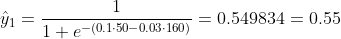
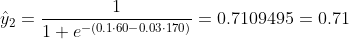
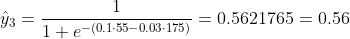
jadi kerugiannya adalah
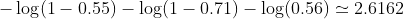
Kemudian Anda belajar algoritma (misalnya gradient descent) akan menemukan cara untuk memperbarui b1 dan b2 untuk mengurangi kerugian.
Bagaimana jika b1 = 0,1 dan b2 = -0,03 adalah b1 dan b2 akhir (output dari gradient descent), bagaimana keakuratannya sekarang?
Mari kita asumsikan jika y_hat> = 0,5, kami memutuskan prediksi kami adalah perempuan (1). jika tidak maka akan menjadi 0. Oleh karena itu, algoritma kami memprediksi y1 = 1, y2 = 1 dan y3 = 1. Apa akurasi kami? Kami membuat prediksi yang salah pada y1 dan y2 dan membuat prediksi yang benar pada y3. Jadi sekarang akurasi kami 1/3 = 33,33%
PS: Dalam jawaban Amir , back-propagation dikatakan sebagai metode optimasi di NN. Saya pikir itu akan diperlakukan sebagai cara untuk menemukan gradien untuk bobot di NN. Metode optimasi umum di NN adalah GradientDescent dan Adam.
